24小时开发阴阳师小程序
玩阴阳师的肝帝们都知道,每天早上5点和下午6点会刷新两次封印任务,每次做任务时最蛋疼的就是找各种怪物对应的副本以及神秘线索。 阴阳师提供了 网易精灵 可以进行一些数据查询,但体验实在太感人,所以大多数人选择使用搜素引擎搜索怪物分布及神秘线索。
而每次使用搜索引擎查找又十分不方便,所以笔者决定写一个查询阴阳师妖怪分布的小程序,力求做到使用快捷体验更快捷,把更多的时间留给狗粮和御魂。
恰好上周末有两天时间,所以立马开写。
1.构思与设计 ( 3小时 )1.1 构思
要做的小程序主要功能就是查询功能,所以主页应该像搜索引擎一样简洁,搜索框是肯定需要的;
主页包含热门搜索,缓存最热式神的搜索;
搜索支持完整匹配或者单字匹配;
点击搜索结果直接跳转到式神详情页;53. 式神详情页应该包含式神的图鉴、名称、稀有度、出没地点,并且出没地点按妖怪数量从多到少排序;
加入数据报错及提建议的功能;
支持用户个人的搜索历史;
小程序的名字,综合考虑小程序的功能最后决定叫做 式神猎手 ( 其实这是最后开发完成后才想好的 );
1.2 设计
构思好后笔者就开始用笔者半吊子的 PS 水平设计了下草图,大概是这个样子:
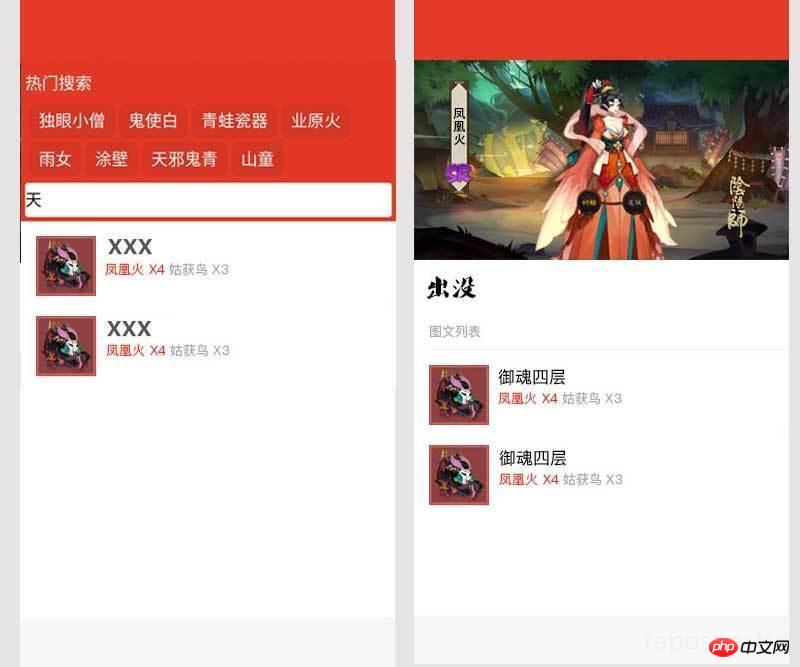
嗯,最主要的首页和详情页设计好就行,然后就可以开始具体考虑怎么做了!
1.3 技术架构
前端毫无疑问就是微信小程序咯;
后端使用 Django 提供 Restful API 服务;
当前最热搜索用 redis 做缓存服务器进行缓存;
个人搜索记录就使用微信小程序提供的 localstorage ;
式神分布信息使用爬虫爬取清洗,格式化为 json , 入库前再做人工检查;
式神图片及图标直接爬取官方资料;
自己制作爬不到的式神图片及图标;
小程序要求 HTTPS 连接,恰好笔者之前搞过,可以直接看这里 HTTPS 免费部署指南
到此,正式开发前的准备得当后,我们就可以开始正式开发了
2. API 服务开发 ( 5小时 )
Django 的 API 服务开发笔者之前经常做,所以有比较完整的解决方案,可以参考这里 django-simple-serializer
之所以花了 5 个小时是因为近 4 个小时在增加 django-simple-serializer 对 Django ManyToManyField 中 through 特性的支持。
简而言之, through 特性就是可以使多对多关系的中间表增添一些额外的字段或属性,例如: 怪物副本和怪物之间的多对多关系就需要增加一个储存每个副本有多少只相应怪物数量的字段 count。
搞定 through 支持后 API 的构建就很快啦,主要有五个 API :
搜索接口;
式神详情接口;
式神副本接口;
热门搜索接口;
反馈接口;
写好接口后添加一些 mock data 以供测试;
3. 前端开发 ( 8小时 )
前端花了最久的时间。
一方面笔者真的是个后端工程师,前端属于半路出家,另一方面小程序有一些坑。 当然,最主要的是一直在调整界面效果,这里花了大量时间。
写小程序的整体体验笔者感觉就和写 vue.js 一摸一样,只不过一些 html 标签没办法使用,而是需要按小程序官方提供的组件进行书写, 这里有一点感受就是,小程序本身组件化的设计思路应该是借鉴了 React 而语法之类的应该是借鉴了 vue.js 。
最后前端开发完毕后主要分为这几个页面:
主页 ( 搜索页 );
式神详情页;
我的页面 ( 主要是放搜索历史和免责申明等等东西 );
反馈界面;
声明界面 ( 为何需要这个界面? 因为所有图片及一些资源都是直接抓取阴阳师官方的资源,所以这里需要申明只是非盈利性质的使用,版权乱七八糟的都还是阴阳师的 )。
哎,丑媳妇早晚要见公婆,这里不得不放最后开发出来的界面图了
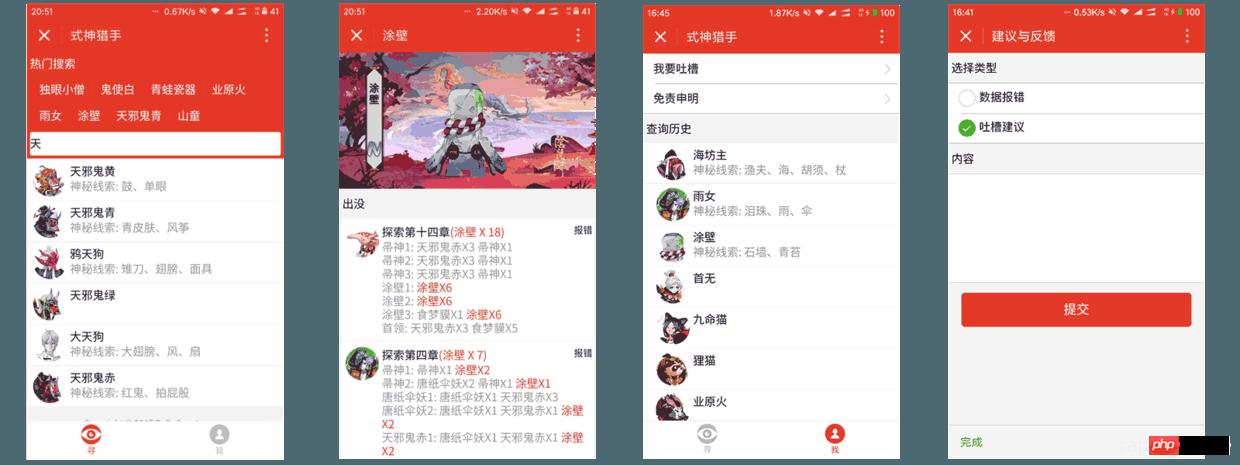
对于微信小程序的入门及基础,笔者就不在这里多讲了,相信到现在对微信小程序有关注的开发者或多或少自己写个简单的 demo 肯定是没问题的,我就主要讲一讲我在开发中遇到的坑:
3.1 background-image 属性
在写式神详情页的时候两个地方需要用到 background-image 属性设置背景图,在微信开发者工具中一切显示正常,但一到真机调试就没有办法显示,最后发现小程序的 background-image 在真机不支持引用本地资源,解决方案有两种:
使用网络图片: 考虑到背景图的大小,笔者放弃了这种方案;
使用 base64 编码图片。
正常来讲,css 中的 background-image 就支持 base64 ,这种方案相当于把图片直接用 base64 编码成一段 base64 码进行储存,在使用时这样使用即可:
[CSS] 纯文本查看 复制代码
background-image: url(data:image/image-format;base64,XXXX);
image-format 为图片本身的格式,而 xxxx 就是图片经过 base64 后得到的编码。这种方式其实是一种变相引用本地资源的方式,好处在于可以减少请求图片的次数,而缺点则是会增大 css 文件并使其不是那么好看。
最后笔者选择第二种方式主要还是考虑到图片的大小以及 wxss 的增大在可接受范围内。
3.2 template
小程序支持模版,但要注意模板拥有自己的作用域,只能使用data传入的数据。
另外,在传入数据时需要将相关数据解构传入,在模版内部是直接以 {{ xxxx }} 的形式进行访问,而不是像在循环中 {{ item.xxx }} 这种访问形式;
关于解构:
[XML] 纯文本查看 复制代码
<template is="xxx" data="{{...object}}"/>